Job: Genia Technology a nanopore-based DNA sequencer

From paper: PNAS 2016 113 (44) E6749-E6756, doi:10.1073/pnas.1608271113
What it’s about
Nanopore-based sequencing is considered the next generation of DNA sequencing with the primary benefit of allowing much longer read lengths. This is important because current sequencing technology can only read short lengths of DNA at a time, and these little snippets are stitched back together with software. Unfortunately the human genome is filled with long repeats longer than the current technologies read length, this can cause errors in the stitching process, thus the importance of this technology.
The nanopore based sequencing at Genia works through a combination of a computer chip, nanopore, DNA replication, and chemically tagged free nucleotides.
The foundation starts with the computer chip. It’s most similar to a image sensor in that it monitors an electrical current in massive parallel. Each pixel sensor in a standard image sensor is a “well” for our chip. Each well will have one bilayer and one nanopore. Electrodes on each side of the lipid bilayer drive a small electrical current, and the only part that closes this circuit is the opening in the lipid bilayer from the nanopore. By constantly monitoring the electrical current, we can monitor the state of the nanopore.
Now the single stranded DNA that you're trying to read is copied with a DNA polymerase enzyme. While the copying process is occurring, it needs to pull in free nucleotides (an A, T, C, or G) to generate the copy. These free nucleotides have been chemically modified to include a chemical tag that causes a specific electrical change when it's blocking the nanopore. Each base has a specific tag that causes a different electrical signature. The tag on the free nucleotides is cleaved as the DNA replication process continues. And the tether keeps the nanopore and DNA polymerase in close proximity to facilitate the threading process.
Finally the signal is analyzed by sophisticated software to produce the base pairs of the target DNA sequence.
And that's how it works in a nutshell.
I think one of the great things about working there was being able to meet some truly talented individuals who are masters of their craft. It really pushes you to keep learning and growing. In addition, it was fun to be in a position that worked on problems that can span molecular biology, material science, chemistry, physics, electronics, mechanical engineering, software, manufacturing processes, and laboratory processes.
But when I first joined, I was like holy crap. Would I really be able to contribute in any way to this crazy cyborg nanomachine project? But over the course of the year, I saw time and time again the amazing contributions one can make purely by having a different perspective, asking different questions, and setting different priorities.
Hardware lifespan project
The system engineering team I was a part of was assigned the hardware reuse project. Since the wet sequencing reactions occurred on top of the computer chip, after one use we had to throw the whole computer chip away, since at the time there was no way to clean it. This was what we needed to improve. The reuse project required the use of new technologies that for some reason did not work with our existing processes. Therefore it was a problem that existed somewhere inside a gigantic problem space.

Fractal space or problem space?
So basically the approach I took to this problem was designing experiments that specifically cut down this problem space or helped me characterize the problem in some way shape or form to point me in the right direction.
Unfortunately I can't really discuss more without getting into the specifics. But I really wish I could, because it turns into a very scientific version of a murder mystery. But at the end of the day we discovered a fairly un-obvious problem that required a different model of how our process originally work.
Of course, I continued to run more experiments changing key parameters, such that if this really was the problem, we should be able to expect a certain outcome, and those follow-on experiments were also successful.
This quickly led to meeting 1 out of 5 product goals (to reuse the chip 10 times) for the whole company (a heavily funded Roche acquired size company) a whole year ahead of schedule by one person (because I mostly worked on my own setting my own direction and experiments). I found out later on that the process I came up with actually greatly exceeded 10 reuse cycles. Overall, the economic impact of my work is at least in the millions of dollars.
Signal Analysis Algorithm
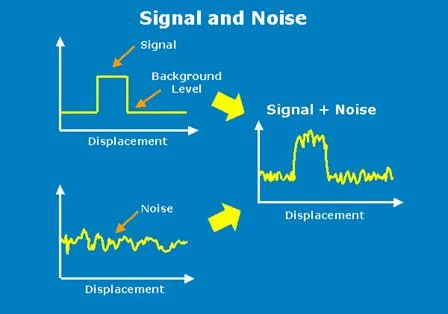
Since the DNA sequencer works by measuring electrical impedance across a nanopore caused by molecular events, there's going to be noise and a lot of data. So how do we create an algorithm that'll pick out the needle in the haystack?
Well clearly you'll need to find efficient methods, but luckily we can stand on the shoulders of giants. Numpy with their array operations offered huge performance improvements over simple python implementations where you iterate over a list. We're talking about I forgot I was using a python list comprehension rather than a numpy array operation at one single point in my analysis script, but it was contributing to an additional half an hour of processing time.
Now we can build on these primitive features, and discover creative ways to identify the signal from the noise. Again can't discuss too much into the specifics, but one take away that really got hammered in from this project was memory management.
Initially I was holding the entire dataset in memory, and it worked fine for a single dataset. However, I started to run batch tests on multiple datasets, and quickly ran into my computer freezing up.

Then I went through my code and realized what I was doing was running these large bulk transformations on the dataset in series. This required that I store the entire dataset and it's permutations in memory.
However, I found a way to break down the computation, so that I could store much less information in memory, while still conducting the necessary bulk analytics. Basically I needed to finish computing each individual signal to a certain checkpoint, and then saving the much smaller result before moving onto the next signal. Then I could run whatever bulk statistics I needed at that checkpoint, and continue to proceed with the analysis.
This change in the script reduced the memory usage from a completely frozen computer to something around a few hundred megabytes of memory usage while still working with gigabyte sized files. In addition, this computational setup lends very well to parallel processing. So as the dataset grew, we could utilize additional cores cutting the compute time in half, quarters, etc.
In addition, another key take away that I learned from this project is that generating an artificial dataset to train a machine learning algorithm is a viable approach depending on the problem.
When it comes to using a machine learning algorithm, there's choosing the particular algorithm, there's choosing the settings to the algorithm, but ultimately you're teaching it through the training set.
Now let's say I was trying to teach it to identify stop signs. Now is it 100% necessary to run out and grab thousands of real world stop signs in order to be used as a training set? If the classifier was meant to be used in the real world, the real world training set would be the golden standard for training sets.

But is that to say there's no value in using an artificially rendered dataset of stop signs at various angles, lightning conditions, backgrounds, wear, etc? There definitely still is.
First off, this modeling approach gives you essentially an interface to teach a machine learning algorithm. You can set all the various properties that are important, and use various noise that you'd find in real world conditions, so that the machine learning algorithms focuses on the right features while ignoring others.
Secondly, this real world dataset isn't guaranteed to be perfect anyways. Maybe that dataset could be skewed in a way that doesn't represent the full range of a feature. For example, let's say maybe the real-world dataset was taken at a location near the equator where sunset and sunrise are relatively short. Or the training set was derived from Google Images, but most photos were taken just during daytime lightning conditions. The training set would be missing a lot of these brown-orange tinted stop signs, and may not properly generalize when it sees it in the real world.
Finally, it might not be feasible to gather real world data. Machine learning has been used to generate novel mechanical designs, but they don't manufacture and measure each iteration. They generate a starting CAD model, allowing the algorithm to make various 'mutations', and using simulation software to measure the results. This is an artificial dataset.
Therefore artificially generated datasets are a useful tool, but as with real world dataset care must be taken to ensure that it properly represents that conditions in which the machine learning algorithm will be used.
At the end of the day, the machine learning algorithm trained with an artificial dataset was able to pick out the signal from the noise with better accuracy than my custom algorithm. However, this was only the case in extremely high noise conditions, which was a small minority of the dataset. The machine learning algorithm was also unfortunately relatively slow, since it involved a sliding window implementation. Adding on roughly an hour to the analysis, while only improving the accuracy maybe a couple percentage points.
Therefore it was removed and the ensemble algorithm was reduced to just my custom algorithm, which already offered good performance sifting through gigabytes of noisy signal data within half an hour while still providing roughly 95% accuracy.
Processes

Definitely not the DNA sequencer, but similar in complexity
One of the great things about understanding the various processes that are occurring from the molecular to the macroscopic stage and from the hardware to the software is the clarity at which you can observe problems.
For example, there are multiple cases where understanding the molecular scale interactions is critical to understanding a macroscopic failure. And on the flip side, understanding the impact of macroscopic interactions on a molecular scale. It was this understanding that helped me ask different questions that helped me define the problem, and ultimately lead to solutions.
In addition, it was this understanding that helped clarify even non-technical issues. For instance, very early on the system engineering team (which I was in) originally had goals that depended heavily on whether other teams were able to meet their specific goals, something we had no real control over while our hands were already full dealing with the specific problems within our domain. And it was this feedback that eventually got the team goals redefined to better represent what was within our control, what we should be responsible for, and what can be expected, which is a very important mutual understanding.
Wrap-up
Overall, I get the feeling that my degree in molecular biology where we were hammered with experimental design, my programming experience where failure analysis is something you do all the time, plus my extremely interdisciplinary background were the key elements that really helped me succeed in this position.
For instance, sometimes I just ran a negative control and I found something. It was super easy, but because I have that mindset, I ask those questions.
And finally I saw the importance of stating your opinion, defending it, and proving it, if you really believe it's right. I was told multiple times I was wrong, even though at the end of the day I was right. And that's not to say, they were in the wrong. They were just arguing their point of view, which is what they should be doing.
But if you know something they don't, it's your responsibility to explain it. That's how you make your contribution.