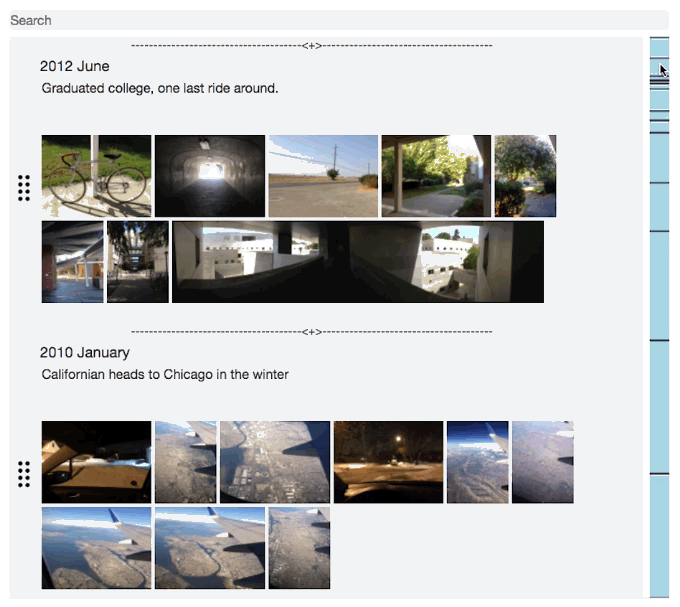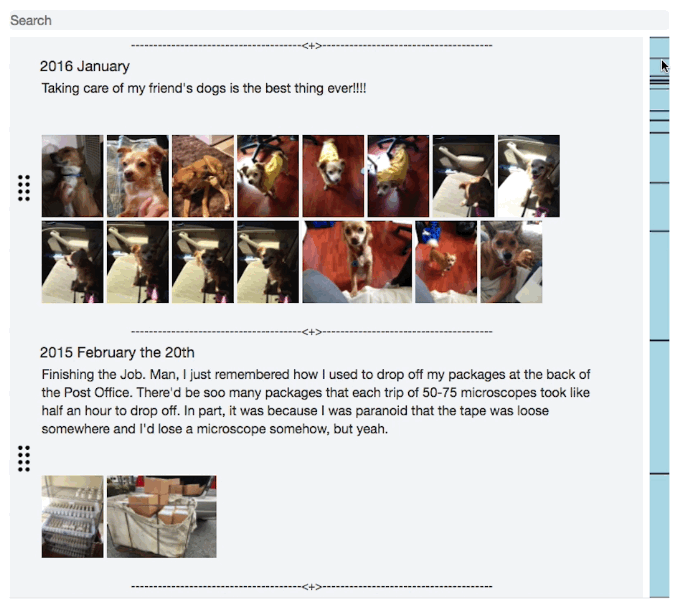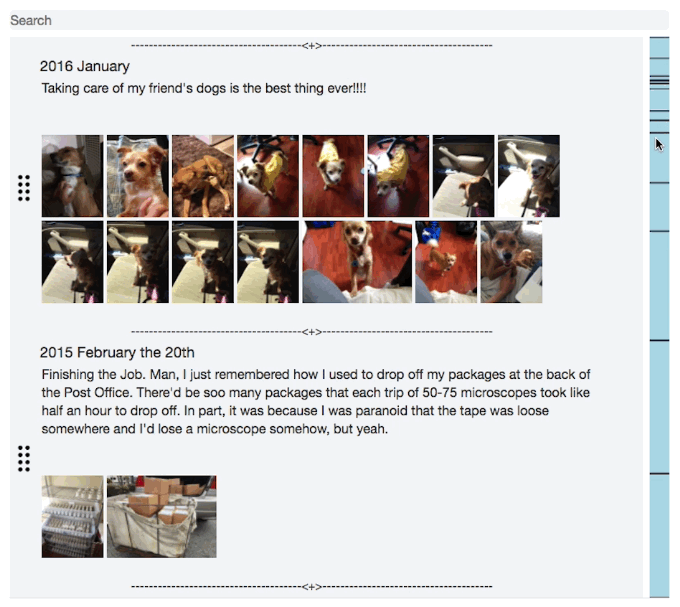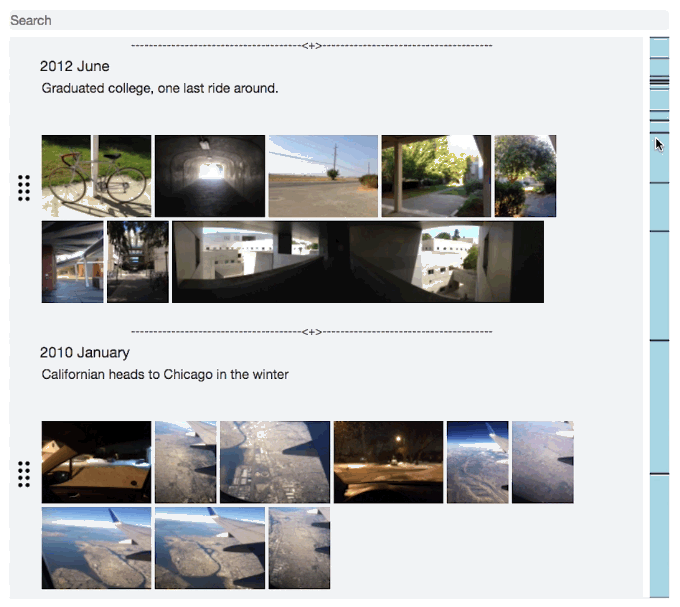
Startup: Journal Light Web App
The Motivation
I just remembered a moment in my life, I was visiting Santa Cruz with my friends, standing in the tide, letting the the sand run between my toes, and staring out into the ocean.
And because the tide was rapidly coming in and I still wasn’t moving, my friends started shouting from a distance “Are you okay?!”
But really I was just throughly enjoying the sand running between my toes, and also curious how deeply I'll sink into the sand, since the tide washed a little out from underneath me each time.
It was a great moment in my life, and I tell myself, I’ll never forget that moment. But will I?
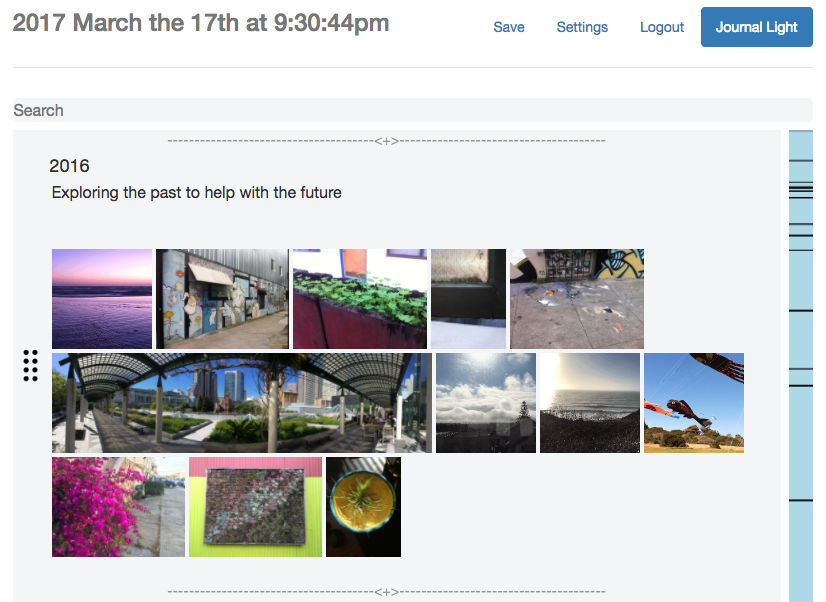
I started to think about what makes us who we are, it’s not just where we’re going, it’s also very much where we’ve been. After looking through my old photos, which goes back over 10 years, and thinking back to Everything that’s happened. My life felt more like an epic like the Odyssey rather than a short story. And what I realized is that it’s just because of what you can remember at any given moment. We constantly forget the details and moments that define our story.
And I wished I captured more of the details. There’s huge gaps in between the photos and even those only capture a part of the story, but I still remember a fair amount around each one. So I wanted to start keeping a journal, but I struggled. I’m really busy and don’t have time to journal regularly. I needed a journal that made it easy to catch up on journaling, but also let me record these random flashbacks that I'll never remember again, and just be able to record past entries more easily.
It is really tedious to have to create the entry, check the date of an entry by referencing another event, and then change the date. All I want to do is just add an entry next to this one! And that’s when I figured it out, there might something I can build, not just for me but for everyone.
Plus I needed a full stack portfolio piece. And that’s how Journal Light started!
Technical - sorting on partial information
Probably the first and foremost issue was finding a way to have this fuzzy representation of the time of an entry while still being able to sort it based on the information available.
Basically what I ended up going with was an array specifying the [year, month, day, hour, minute, second] along with the precision of the entry which could be none, year, month, day, hour, minute, or second.
Now this is where I needed something special, I needed a custom sorting algorithm. For example, if I was ordering by most recent, this is what I would expect as an output given the input:
### Input ###
2015
2016 Mar
2016
2016 Jan
### Output ###
2016 Mar
2016
2016 Jan
2015
### Input ###
2016 Mar
2016
2016 Jan
2016 Dec
### Output ###
2016 Dec
2016 Mar
2016
2016 Jan
So I ended up creating this divide and conquer style recursive sort algorithm.
Essentially what it did was:
Select the entries by precision starting with the lowest
Sort that layer based on that layers information
Remove that layer's entries from the list while recording it's index position, and appending it into another list
Select the entries with the next higher level of precision and repeat
Once the recursion had bottomed out it would reconstruct the sorted list by:
Select the entries by precision starting with the highest
Insert sorted entries back into list based on index position
Select the entries with the next lower level of precision and repeat
There is still a quirk to this algorithm. For instance, the current implementation will do this:
### Input ###
2016 Mar
2016 (a journal entry between January and March)
2016 Jan
2016 Dec
### Output ###
2016 Dec
2016 (a journal entry between March and December?)
2016 Mar
2016 Jan
Even though we probably would've expected it to be more so along the lines of this:
### Output ###
2016 Dec
2016 Mar
2016 (a journal entry between January and March)
2016 JanTo get this result, it requires that use of contextual information to figure out the proper placement, which can become very complicated and computationally expensive.
But the design perk to sorting a journal is that it'll be sorting at most one change at a time. Since the user can at most add, reorder, or change one entry at a time. So even though we can deal fairly well with a completely randomized list, this helps avoid unintended effects due to this quirk. In fact, due to only one change at a time, we can limit the number of changes from sorting a list, and cancel the sort if it threatens to scramble the user's ordering.
In terms of analyzing the worst case compute performance, it's about N^2. Since it's using the javascript sort, which is a bubble sort. Even though it's sorting each sublayer making it technically the sum of each layer subsetN^2, the worst case scenario is a user having everything on a single layer thus N^2. In addition, we're just using basic list insertions which have N performance, and so roughly N^2 to recreate a list via insertions. So after combining the sorting and inserting, it's still roughly N^2 in compute performance.
In terms of analyzing the worst case memory performance based on the algorithm, it's about N. Although there are subarrays created for each layer in sum it's still equal to the size of the whole array, since we're removing elements from the array and adding it to the subarrays or the reverse during the reconstruction. The actual implementation takes up a bit more space, since we're not removing the elements from the main array right away, since it would shift the array positions making the for loop error out. I could have done this in reverse, but I just wanted to keep it simpler for the time being. In addition, I copied objects often times, so that I could see what was happening at each stage.
But hey it works and journaling technology has advanced!
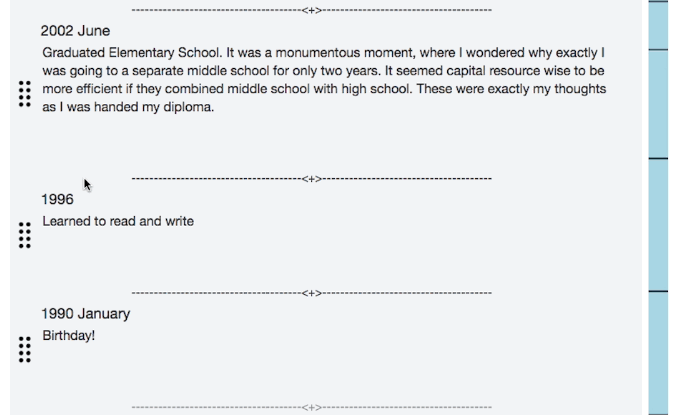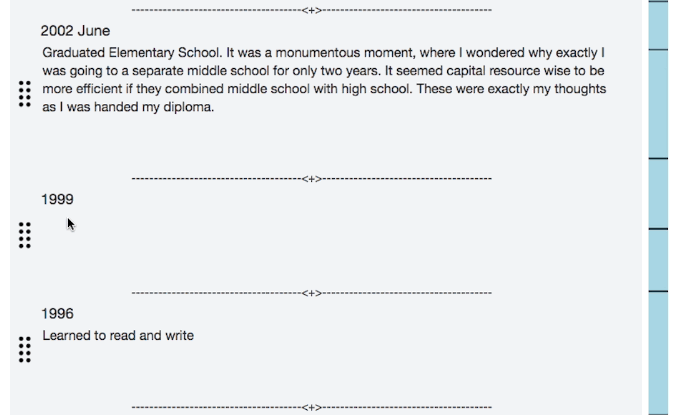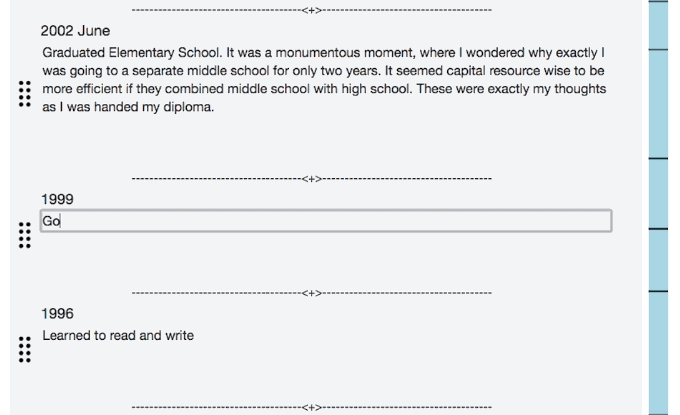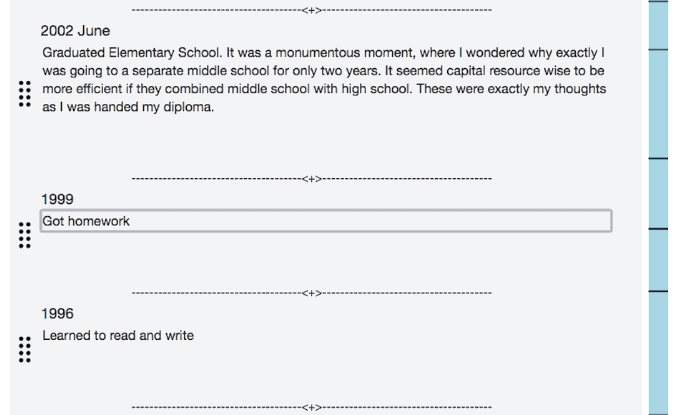

Technical - Variable Size Lazy Loader
Another issue that needed addressing was that I was determined to have everything on a single page. No we won't be click to go to another view that shows the full journal entry, I demand everything on one page! Hahaha, now that I know code, I can fulfill my maniacal desires.
So I've never written a lazy loader before, so the first thing I did was research. And apparently it works by offsetting the scroll according to how large the component you're loading is. So every time you reach the bottom of the page, a say 100px height component is loaded, and at the same time the scroll is offset by 100px.
Unfortunately there is no offset method, it's a scrollTop(val) method that sets the scrolled position of the window. The value parameter defines where the top of the window is in the scrollable element if all visible.
So when going loading the bottom component, it's calculated based on the combination of the total height of the scrollable element if all were visible minus the height of the window to the scrollable element minus the actual height of the loading component. Luckily when loading the top component, it's just the height of the loading component.
Now in order for a seamless experience, it all hinges on this offset scroll matching the size of the loading component down to the pixel. This is why everyone likes to use components that are the same size for lazy loaders, because it's much simpler. The size of the components to be loaded are the same as the ones already on the screen.
Unfortunately the auto-sizing text area component that I imported doesn't determine the size immediately on load. Initially it has a height of 0, and once it calculates how much text is there and how big it needs to be, then it has a height. So I managed to get around this problem by using a placeholder paragraph element with the same text and CSS, as well as a onFocus listener to switch the placeholder with the actual text-area. Overall, this got the desired effect, while improving performance and providing a better UI design.
But also unfortunately I have to load a gallery of photos asynchronously, so we don't really know the total size of the component until that's done or do we?
So the solution was similar to the previous one. I grabbed the photo dimensions on upload, and saved it along with the photo data. This way when the component is loaded, the photo dimensions are already preloaded with a placeholder image say a loading wheel.
Now the full dimensions of the component are specified on load, which will be called back to the main window to use in the offset. Overall, creating this smooth buttery experience where we can seamlessly scroll through our journal :)

The aspiration
Unfortunately there's additional details that I wasn't aware of. Specifically, the way the scroll wheel works is different from the arrow key or mobile touch scrolling!
So typically I set the lazy loader to trigger when it's essentially at the very bottom of the window. Since if there's a remainder, that needs to be accounted for as well. Now the mouse scroll wheel is very good at getting to the very bottom, but the keyboard arrow keys..... not so much.
The keyboard arrow keys move a set jump distance. And if you're close to the bottom and the remainder is less than the jump distance, it won't move. This means the lazy loader won't trigger.
Then there's the mobile touch scrolling. So mobile touch scrolling has those really fancy physics based scrolling effects. Unfortunately that takes precedence over lazy loading. So instead of the lazy loader just firing off as quickly as it can, the scroll will (on iOS) bounce off bottom then lazy load the next element.
Overall, there's a number of problems, and this implementation will need to be reworked. Either by utilizing an existing lazy loader and finding a way to shoehorn this variable height callback in or designing a new lazy loader implementation that manipulates component position with overflow hidden.

It looks like it's just scrolling, but it's actually lazy loading and it's beautiful
Technical - Companion AI

So obviously we're not going to try to build something like the AI in her, but it did inspire me to consider it, and see what could I do with the current resources/tools.
Part of what makes an AI companion for a journal attractive is that it isn't a real person, and as long as privacy is ensured, people are more comfortable sharing what's on their minds and in their hearts.
So how do we do this? Well, recently there was a bot that supposed passed the Turing test, which is the point at which a person can't tell if they're chatting with a human or a robot. However, unfortunately they did so by pretending to be an easily distracted child who primarily spoke another language. Clearly this would not be beneficial towards helping someone write a journal.
And that's exactly what I realized, the goal isn't to try to fool someone it's a human, the goal is to just try to help someone write their journal. And that is a much more accomplishable technical goal than the former.
Luckily since I had a curiosity in psychology and I read rather diversely, I learned long ago that there was a therapy bot that was very good at getting people to talk to it. It was called ELIZA. It worked primarily by using simple filler question like "How does that make you feel?" and reflecting your statements back to you as a question. So if you said, "I'm not sure if I can do this." It'll respond with "How long have you been not sure if you can do this?" through simple regex patterns.
There was a python implementation that I was able to grab and it was a strong starting point. And I added on some simple stuff like having different questions whether your at the beginning of an empty journal entry versus in the middle of one. So I would have questions like "What was the best part of today?" if at the beginning versus using ELIZA for something in the middle. But given the number of tools currently available can't I do better? And quickly my attention turned towards natural language processing.
So I looked into IBM Watson and Google Natural Language Processing, summarization tools, and overall I found that there were a two relatively accurate fundamental legos that I could work with: sentiment analysis and summarization. (The syntax analysis looks pretty good but it'd take a decent amount of work to get something useful from that).
But how do I take these really fundamental tools the sentiment of something and being able to summarize something, and put it together to get a useful journal helper?

A whole world made out of legos!
It definitely took a bit of thought, but luckily I had partially completed an AI course and remembered about the concept of a heuristic. A heuristic is a rule of thumb, kind of like saying major cities tend to be on the coast. And I came up with an effective journal helper heuristic that can be created through the combination of sentiment analysis and summarization.
Essentially, it would summarize the past say 10 sentences you wrote, and finds the sentiment magnitude (or how strongly you felt) from the summarization. Then it would find the sentiment magnitude of each individual sentence. Now any sentence with a sentiment magnitude higher than the summarization sentiment magnitude would be of interest. The idea is that clearly you feel strongly about this, but it wasn't the main topic of discussion. Now we can use ELIZA to potentially reflect this statement back on you or just ask a question like "Can you tell me more about '<insert statement of interest here>'?"
It is a legitimate and powerful way of using the technology we have available today to provide a meaningful improvement to writing a journal.
Now there's still additional improvements that can be made. One of the most interesting is the idea of reflecting a statement back to you as question. Currently it's a very on rails approach with ELIZA that only recognizes particular phrases or a very generic approach with those "Can you tell me more about '<insert statement here>'?" questions.
Ideally the AI could reflect any statement back into a question. One way to fix this is by using a neural network. It would be trained with statements as the training set and the reflected statement question as the label. In addition, here it would be beneficial to include the syntax analysis of the both the training and label set to help it understand how to convert the sentence. However, that is for another time, but it is definitely a viable approach. Generally the sentence reflection process only requires modifying a few words at the beginning, but even with that there's too many different cases to be covered with regex. In addition, we can use the neural network confidence to decide whether to use the custom neural network response or something more generic like "Can you tell me more about '<insert statement here>'?"

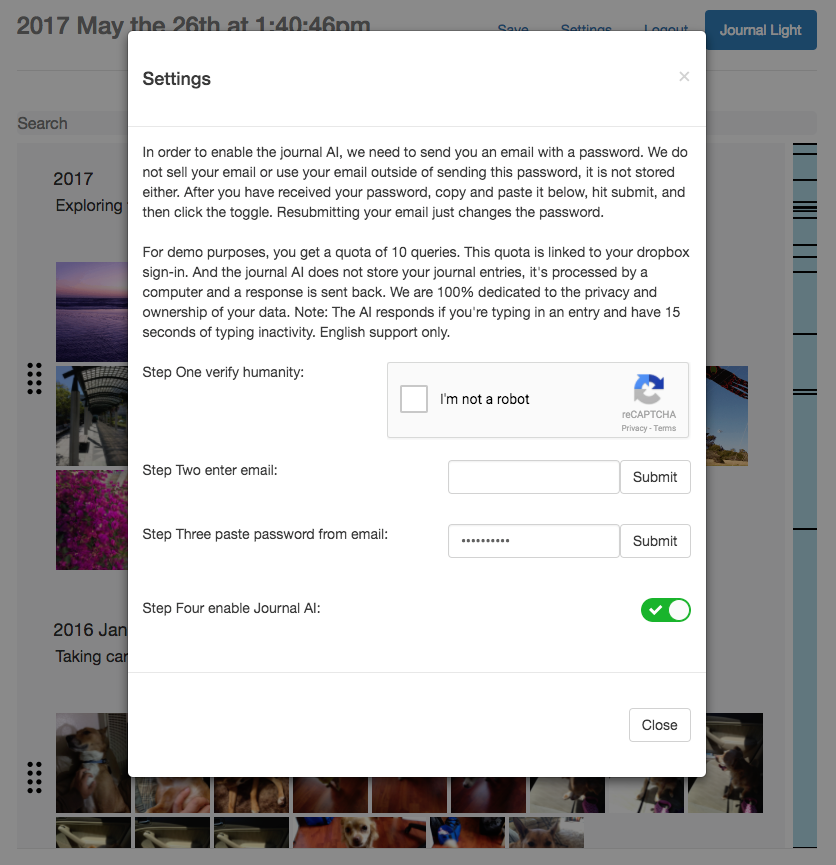
Although it was mostly done in terms of the functional aspects, there were still security issues to be dealt with. Obviously I can't leave a completely unprotected API out there in the dangerous wilds of the internet.
So basically I have users submit their email, so that I can send a unique password to them, which they enter into the Settings page to enable the journal AI.
The email submission API is protected by Google's recaptcha. When an email is submitted the email, dropbox user ID, and recaptcha key is sent to the backend. The server will first validate the recaptcha key, followed by creating/updating a user in the database with the randomly generated password along the dropbox user ID and assigning a quota. Then it'll send the email with the password via SendGrid.
The actual journal AI API is protected by the randomly generated password that is saved on the server side to validate requests, and through the quota. In addition, since we're using Heroku, it includes rate limiting protection.
Technical - Fun Bugs!

Why are they fun? Because they don't make any sense.
So the one problem that was probably the most mysterious was implementing drag and drop reordering with sorting.
I used a library called Dragula, which gave a very easy way to implement an attractive drag and drop system.
Unfortunately for some reason, I could move entries out of order on screen, but according to the React state it hasn't changed. And I can see the reorder action being fired with the correct entries to be moved followed by it being sorted into the correct order. In addition, if I manually modify the order by changing the React user data state, Dragula does update properly.

So what gives?
After probably some soul searching, it finally dawned on me what was going on. Dragula is keeping it's own state to provide seamless animations.
I had seen previously on a React clone of trello where every time I drag and dropped a card, it would briefly flash the card back to where it was originally before refreshing to the position I had dropped it. This is because the drag and drop tool just told React what was moved and where, but it still takes a fraction of a second for React to update that card order, and in that fraction of a second you can see the old state.
So Dragula keeps it's own state of the card order, but how does that enable it to have a different order than what I'm feeding it? Basically since these entries were being moved out of order and being sorted back to the original order, what Dragula saw was no change. Since React components update only when there's a change in the data being passed to it, Dragula did not re-render. However, Dragula did retain it's own internal state change with the entry moved out of order, and that was the problem.
Here is the one liner fix:

Yep it was this.emit("change") twice. It's quick enough to be invisible, but will properly trigger Dragula re-render and make everything work :)
Wrap-Up
It currently exists as a rough draft accessible online, if you're interested in checking it out via a test account contact me via Luo.j2010@gmail.com and I'll pass you the information.
There are various areas that can be improved upon for example:
The largest issue specifically with performance is that currently all images are loaded at full-size but just reduced in display size. This is because Dropbox's thumbnail api doesn't support thumbnail conversion of gifs. Gifs are also some of the largest possible files one can end up uploading, since their compression is worse than actual video formats. In addition, I still want to turn this into an application with local storage on the hard drive, in which case I can just pull images from the hard drive on demand. So rather than implementing a partial solution, I'll hold off until I have time to complete it.
There are various edge case bugs and things that are incomplete. For instance, there are some edge cases where adding a new entry sometimes causes the scroll to jump around. Another example is adding new entries at the top defaults to the current date/time, but if one has previously added entries at a future date this creates an improperly sorted list.
Authenticating journalAI api requests via client session user authentication rather than through a emailed password setup.
However, I would call it a presentable state. There's enough breadth and depth to act as a full stack portfolio piece, and also I can use it for my own journaling needs :D
When it comes to it being a potential business, I think the next major area that needs to be worked on is the marketing. Especially since it didn't necessary start with the potential audience in mind, except for myself :)
So is there really a large enough group of people out there who would want to use this product? Because if there is, I would rather run some Kickstarter or something to raise funds to hire people to help me finish building it rather than doing it all myself. Plus it'd be more interesting spending more time working with a team.
And this is where things stand today, working on scoping out potential markets with a feeling that there would be people who'd want to use this...